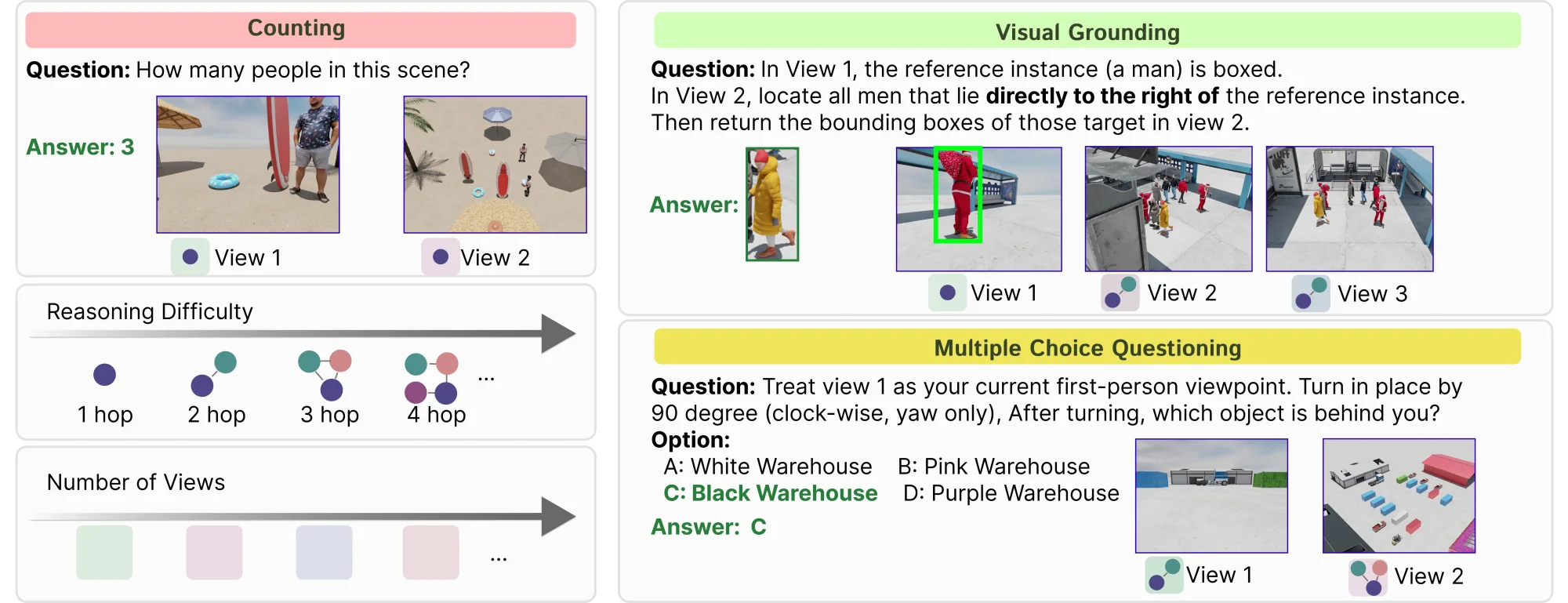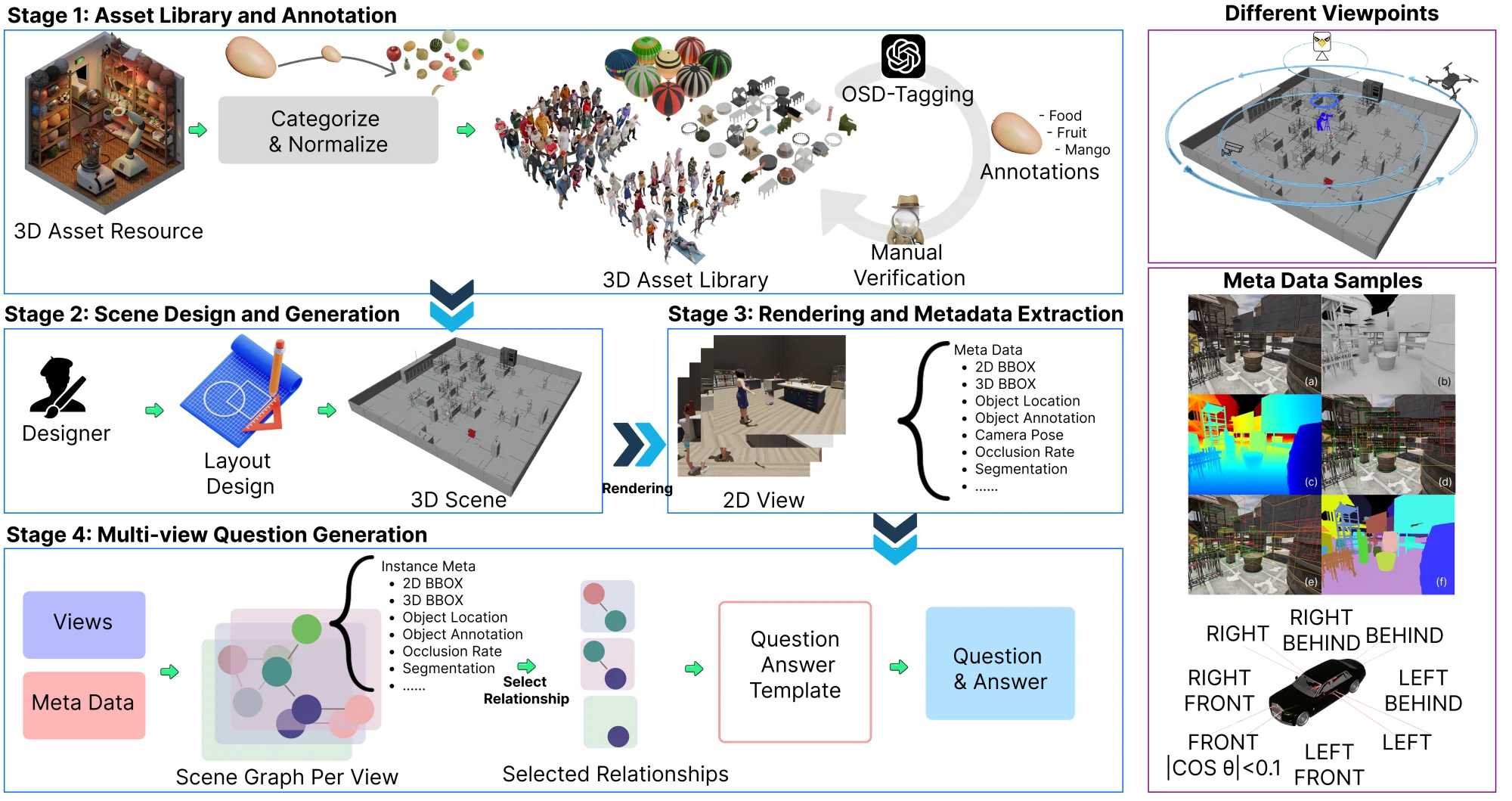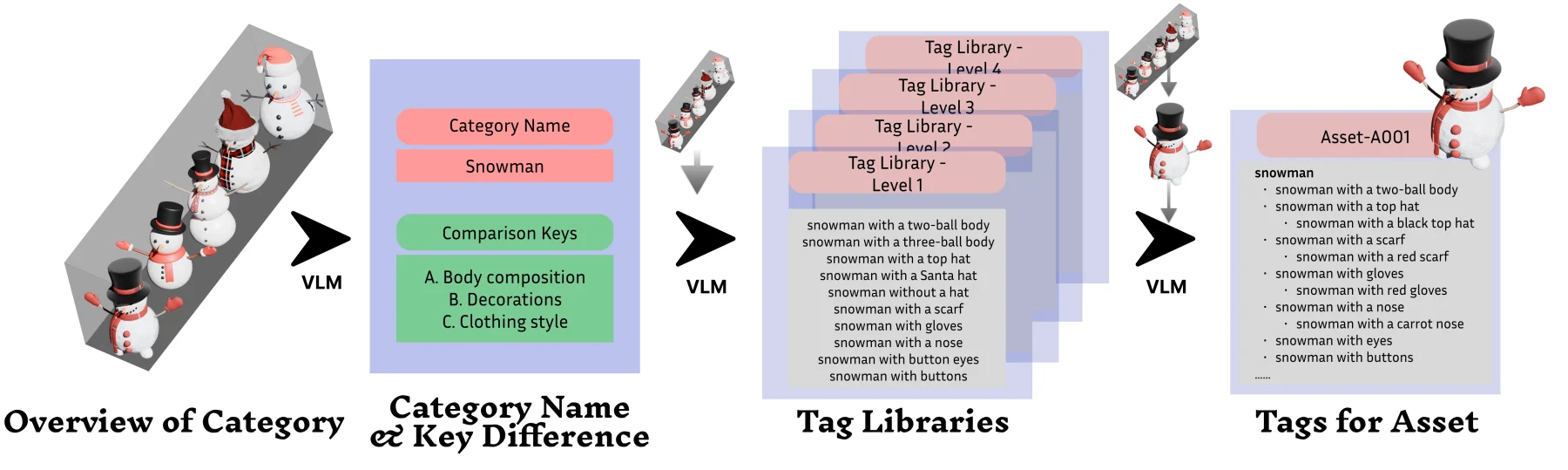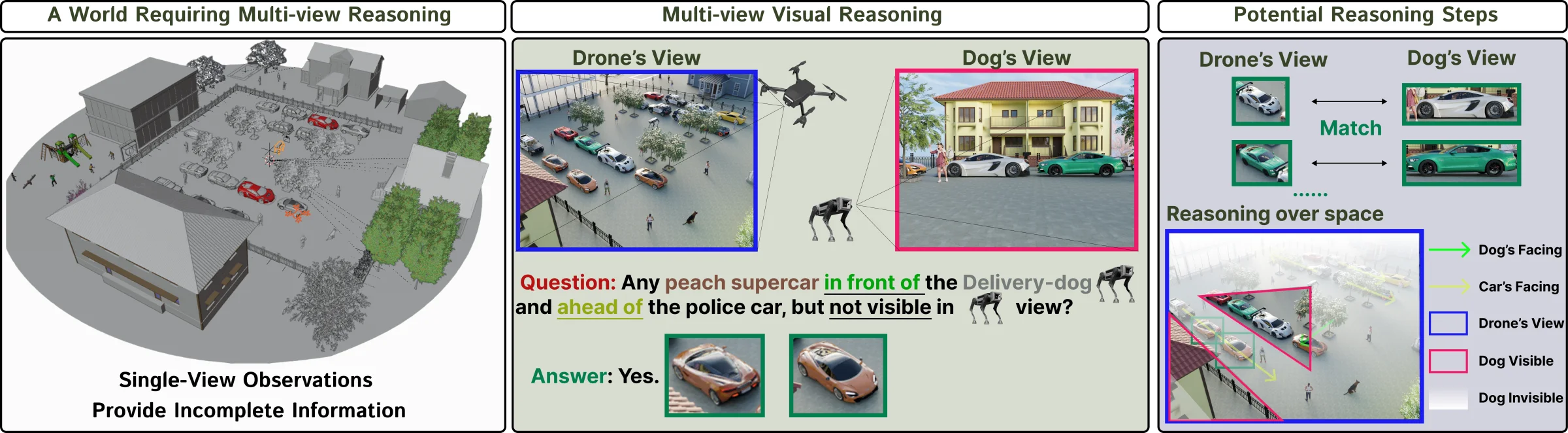
Abstract
Multi-view visual reasoning is essential for intelligent systems that operate from sparse and discrete viewpoints. VIEW2SPACE uses physically grounded simulation to construct diverse, high-fidelity 3D scenes with precise per-view metadata, enabling scalable generation of grounded question-answer pairs for evaluation and training.
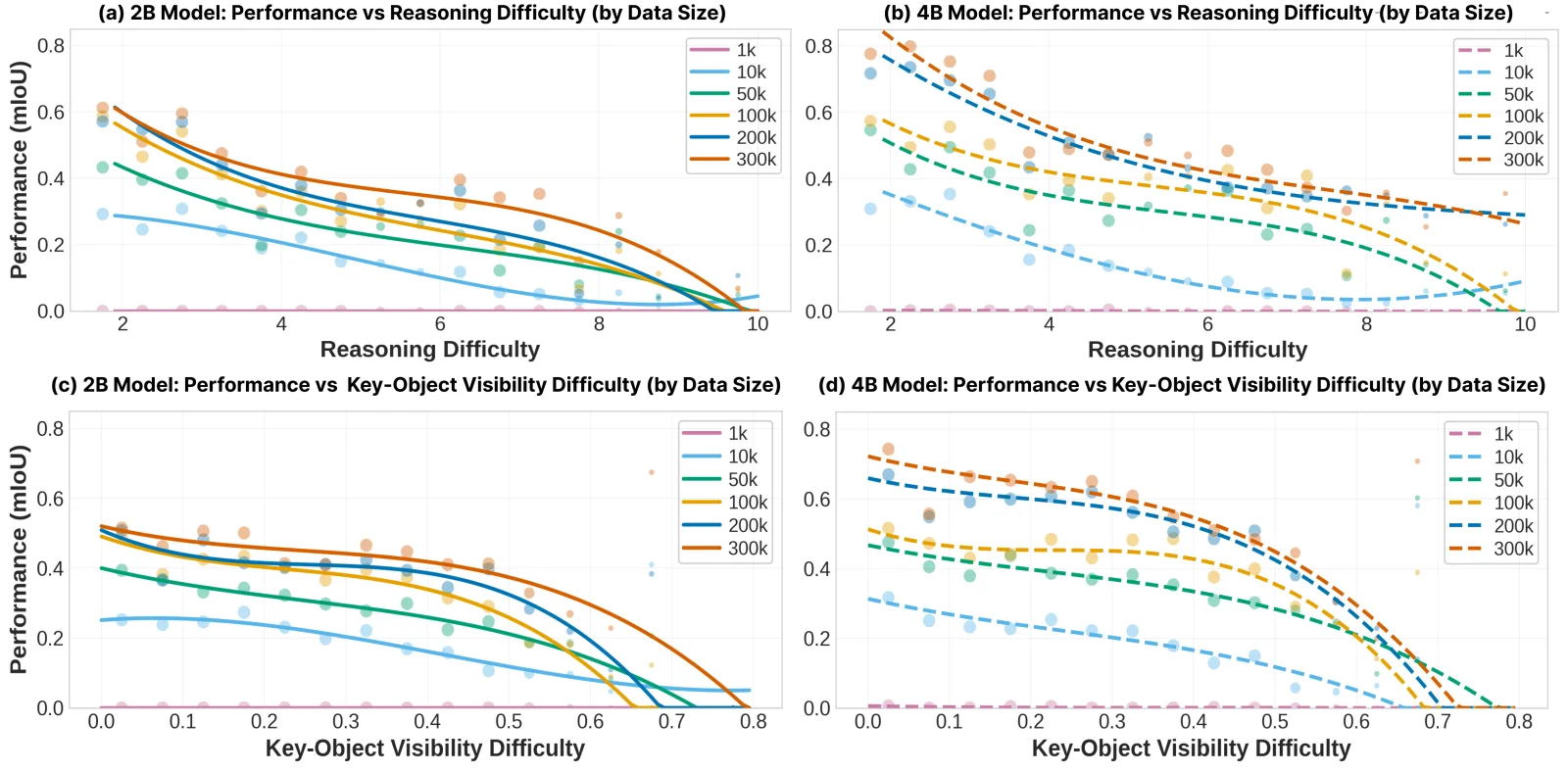
The benchmark shows that current vision-language and spatial models remain far from solving sparse multi-view reasoning. Grounded Chain-of-Thought with Visual Evidence substantially improves performance, while difficulty-aware scaling analyses reveal persistent limits in deep compositional reasoning.